













Abstract
Customized text-to-video generation aims to generate text-guided videos with customized user-given subjects, which has gained increasing attention recently. However, existing works are primarily limited to generating videos for a single subject, leaving the more challenging problem of customized multi-subject text-to-video generation largely unexplored. In this paper, we fill this gap and propose a novel VideoDreamer framework. VideoDreamer can generate temporally consistent text-guided videos that faithfully preserve the visual features of the given multiple subjects. Specifically, VideoDreamer leverages the pretrained Stable Diffusion with latent-code motion dynamics and temporal cross-frame attention as the base video generator. The video generator is further customized for the given multiple subjects by the proposed Disen-Mix Finetuning and Human-in-the-Loop Re-finetuning strategy, which can tackle the attribute binding problem of multi-subject generation. We also introduce MultiStudioBench, a benchmark for evaluating customized multi-subject text-to-video generation models. Extensive experiments demonstrate the remarkable ability of VideoDreamer to generate videos with new content such as new events and backgrounds, tailored to the customized multiple subjects.
Framework
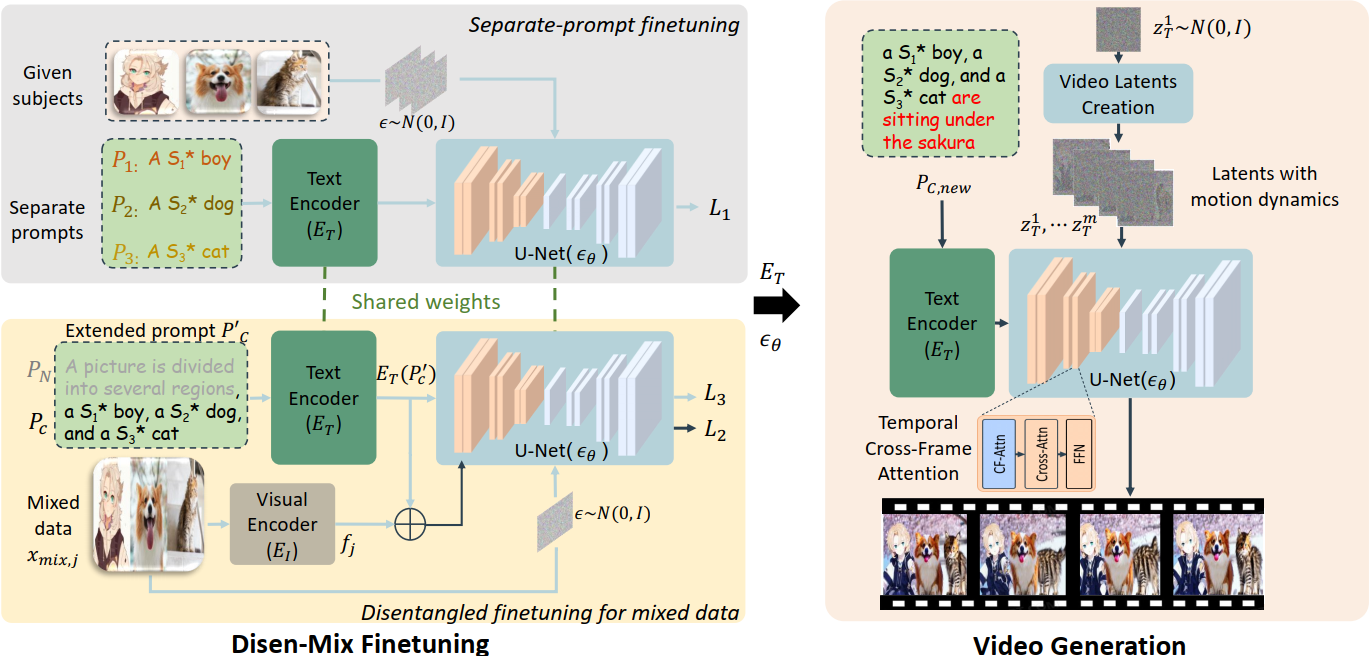
VideoDreamer leverages the Stable Diffusion (Text Encoder and U-Net) as the video generator as shown in the right figure, where the motion dynamics and temporal cross-frame attention are used to maintain temporal consistency among the generated frames. To achieve the multi-subject customization, in the left figure, we design the separate-prompt finetuning for customizing the model with each subject, while the disentangled finetuning for mixed data is designed to avoid the attribute binding problem when generating multiple subjects in the same frame. The extended prompt and the visual encoder are designed to avoid the artificial stitches brought by the mixed data.









































